Flutter Maps With Vector Tiles
Flutter is a huge productivity booster except for a few sharp edges, one of which is embedding maps. Maps are commonly added using the google_maps_flutter package, which uses native platform widgets to embed a Google map in your Flutter app. The resulting map looks and behaves beautifully, except when it doesn’t. The platform/Flutter combination is not perfect, and for my use-case isn’t good enough for a prodution app. This post details the issues that I encountered and how I ended up solving the problem by creaing a plug-in vector_map_tiles to add support for vector tiles to flutter_map.
There were two issues that prevented me from using Google maps in my app:
1. Scrolling Placement
My app presents a map with weather data and various charts. With mobile devices having smaller screens, scrolling is a necessity. This means that the map widget must scroll along with other content.
Flutter positions native platform widgets (platform views) over top of the Flutter view hierarchy. This clever approach to layering make them appear the same as other Flutter widgets. When platform widgets are not included in a scroll view, it works beautifully. When scrolling, the platform map widget is occasionally misplaced. For example, when scrolling vertically, the map widget is placed too high, too low, or gets stuck at the bottom of the screen.
2. Native Crash
To support creating awesome weather visualizations that can be shared on social media like this one, the app has to be able to render maps to an image. To do that, a snapshot of the map is taken and composed with other components. A bug in the Google Maps package occasionally results in a native crash when taking a snapshot. When such a crash occurs, the app is terminated - a terrible user experience.
Tackling the Issue: Failed Attempt
My first attempt to fix the issues was to create my own platform widget package to embed a platform-native Google Map. I knew that I could solve the native crash problem, and was hopeful that I could address widget positioning. After a few hours, I had something up and running, but was unable to achieve a user experience that was good enough. It was clear that any approach using platform-native widgets just wouldn’t work due to the widget positioning issue.
Flutter Native Maps
It turns out that there is a whole ecosystem of mapping alternatives to Google Maps, mostly focused on the web and built in JavaScript. One such library, Leaflet, has inspired an excellent Flutter map implementation named Fleaflet, also known as flutter_map. By embedding a map using Flutter components only, i.e. without platform views, I could avoid all of the rough edges that come with native platform components in the Flutter widget hierarchy.
flutter_map worked beautifully, but had rough edges of its own because map tiles were pre-rendered as raster images and scaled on the client. As a result, when zooming map tiles become slightly blurry, text sizes change, and theming is limited to themes supported by the service offering raster tiles.
Flutter Maps and Vector Tiles
Unlike a raster tile, which is an image, vector tiles instead represent map data as a set of points, polygons, lines and metadata with relative positioning. Clients render these vectors, resulting in sharp maps at any scale.
Another advantage of vector tiles is that map data can be rendered with a variety of themes, meaning that the color of geographic features such as land, roads and water can be any color as defined by the theme. This is especially relevant for mobile devices supporting dark mode.
For flutter_map to produce the beautiful maps that we have come to expect, vector tile support is essential.
Second Attempt: Support Vector Tiles in Flutter
As an experiment I decided to try drawing vector tiles using Flutter and Dart. How hard could it be? It turns out that drawing vector tiles is achievable. Within a few days I had rudimentary support for themes, basic land and water shapes, lines and text as a dart library vector_tile_renderer
I’m learning how to render vector tiles for maps in Dart https://t.co/YRmvpyQwJp #dartlang #maps pic.twitter.com/wxXc3sJGKu
— David Green (@dgreen) May 29, 2021
The commit history tells the story of starting with the simplest possible thing that could work, and evolving the design from there. You can see how the details of the original tile shown in the above tweet evolved too:
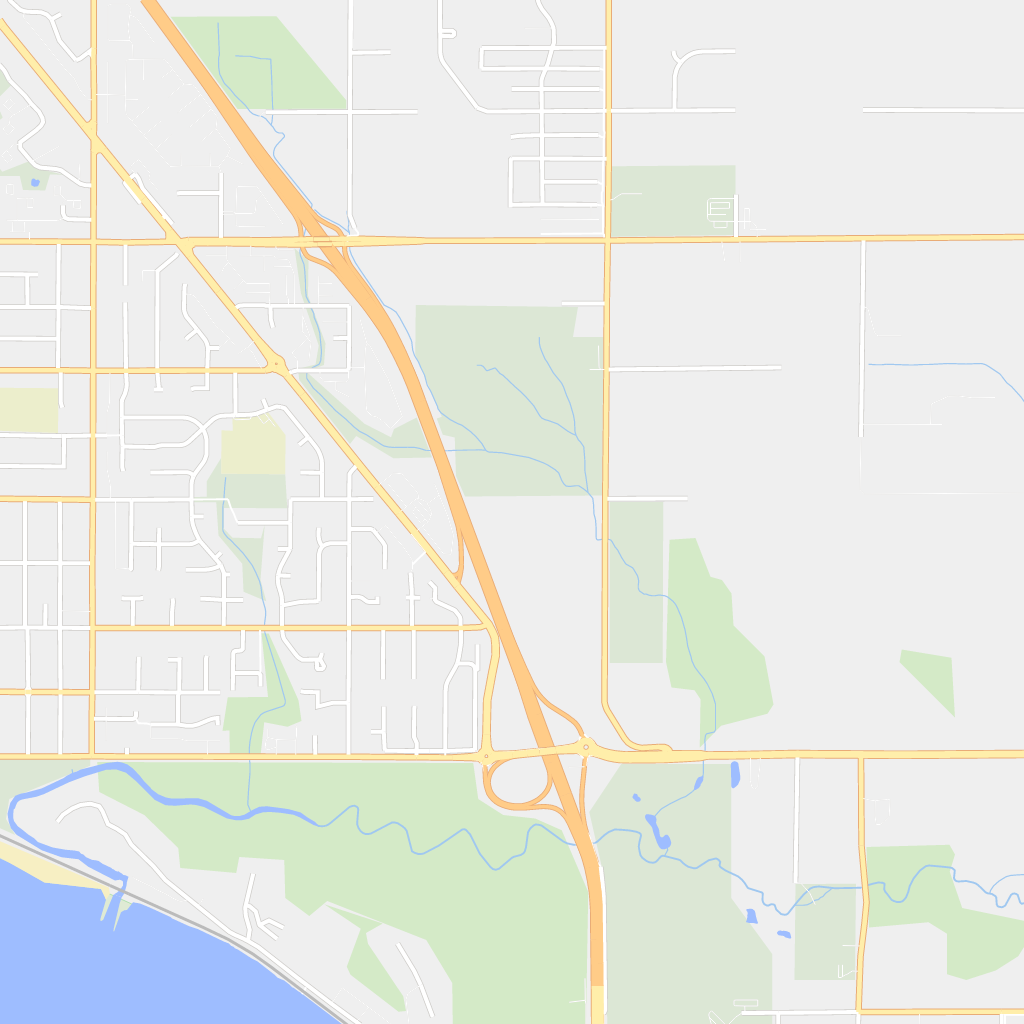
223 commits later, I have added support for vector map tiles to flutter_map with great results:
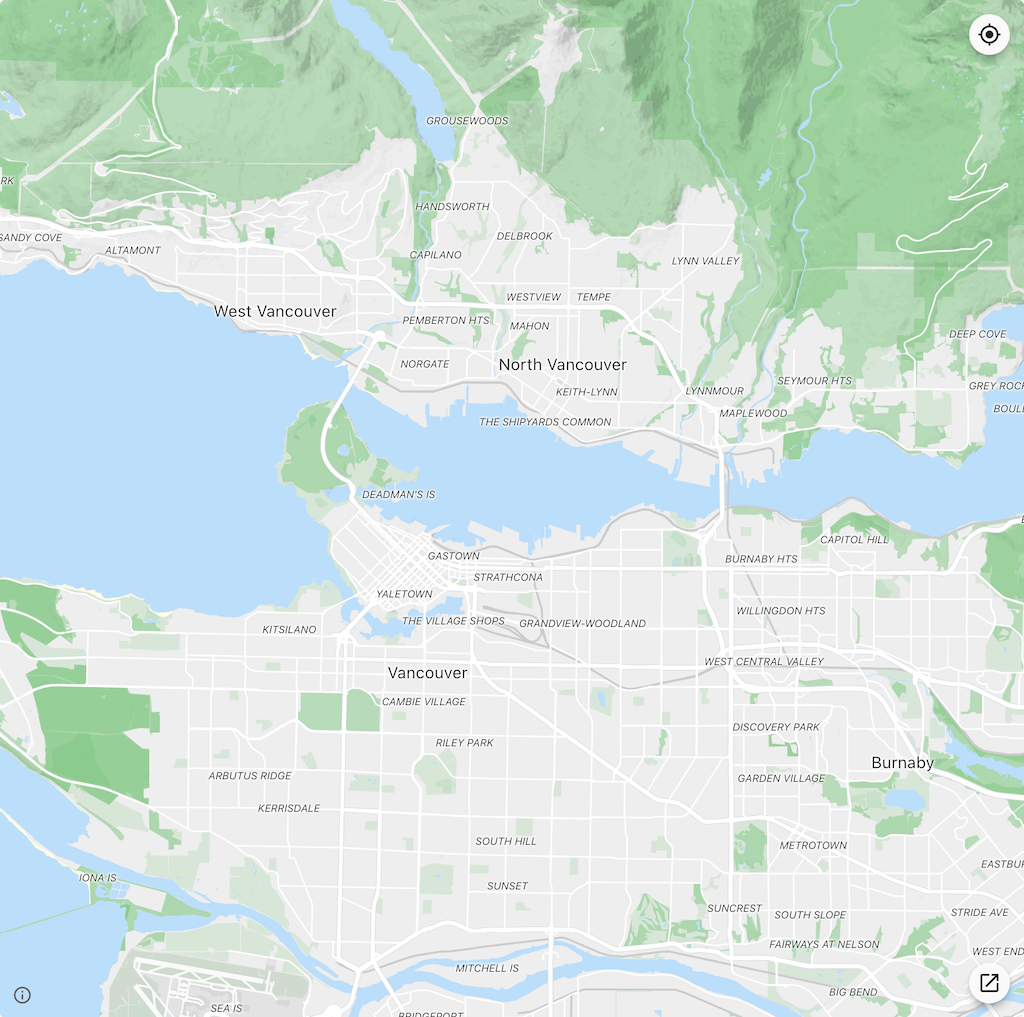
What’s Next
Vector tiles support in Flutter is good, but still needs work.
A major challenge is performance: Flutter needs to render each frame in less than 16ms in order to achieve 60 frames per second. Flutter uses the Skia framework to render Canvas rendering operations efficiently. Despite using Skia, which renders directly to Metal on iOS, map vector tile rendering can be slow enough to drop frames during animations.
Another area for improvement is more complete support for themes and theme styles. Currently, some theme style syntax is unsupported so it’s not possible to pick some existing themes and have them work as-is.
While there is more that can be done to further improve vector tile support in Flutter maps, it’s currently good enough that I’ve been running it in production now for several months. If you want to try it out, feel free to run the example app or check out my app Epic Ride Weather which is available on Google Play and the App Store.
maps attribution: Copyright Stadia Maps, OpenMapTiles, OpenStreetMap contributors
Recent Posts
- Flutter Maps With Vector Tiles
- Raspberry Pi SSH Setup
- Raspberry Pi Development Flow
- Troubleshooting Android App Crash on Chromebook
- Article Index
subscribe via RSS